FT-LLM 2026 数学タスク — チーム ビクトリー
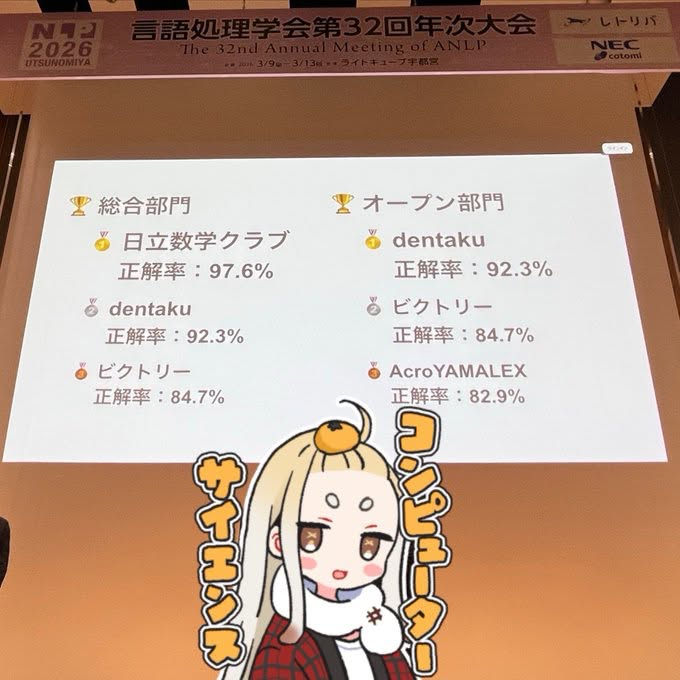
FT-LLM 2026 の数学タスク オープン部門に参加。チーム「ビクトリー」として総合部門3位、オープン部門2位を獲得。
LLM Math Fine-tuning SFT GRPO Majority Voting
概要
FT-LLM 2026 チューニングコンペティションの数学タスク オープン部門に、チーム「ビクトリー」として参加しました。結果として、総合部門で3位、オープン部門で2位を獲得しました。
今回の取り組みでは、与えられた 8B ベースモデルを出発点として、層拡張による 12B 級モデル化、長文 CoT による SFT、GRPO による事後学習、多数決による推論を組み合わせて数理推論性能の向上を目指しました。
期間 / 体制 / 役割
- 期間: 2026年3月
- 体制: 8名チーム「ビクトリー」
- 役割: TIR 用データセット生成、推論システム構築、事後学習、評価、レポート執筆
主な取り組み
- 多数決(Majority Voting)による解答抽出と文字列正規化
- 32層から48層への層拡張による 12B 級モデル化
- 長文 CoT を用いた SFT と GRPO による事後学習
- 学習から推論、評価までを通したパイプライン構築
結果
- 総合部門: 3位
- オープン部門: 2位
- チーム名: ビクトリー
所感
入賞できたのは嬉しかった一方で、個人的にはかなり悔しさの残る結果でもありました。1位チームの解法の中核が、自分が実装を担当していた TIR の方向性だったためです。
自分たちも TIR を検証しており、有効性そのものは確認できていましたが、最終提出系には載せませんでした。実装の安定性や統合コストを考慮した判断ではあったものの、結果を見るともっとやれたことがあったのではないかという気持ちは強く残っています。チームのメンバーに対しても申し訳なさがあり、同時にこの悔しさを次に活かしたいと思っています。